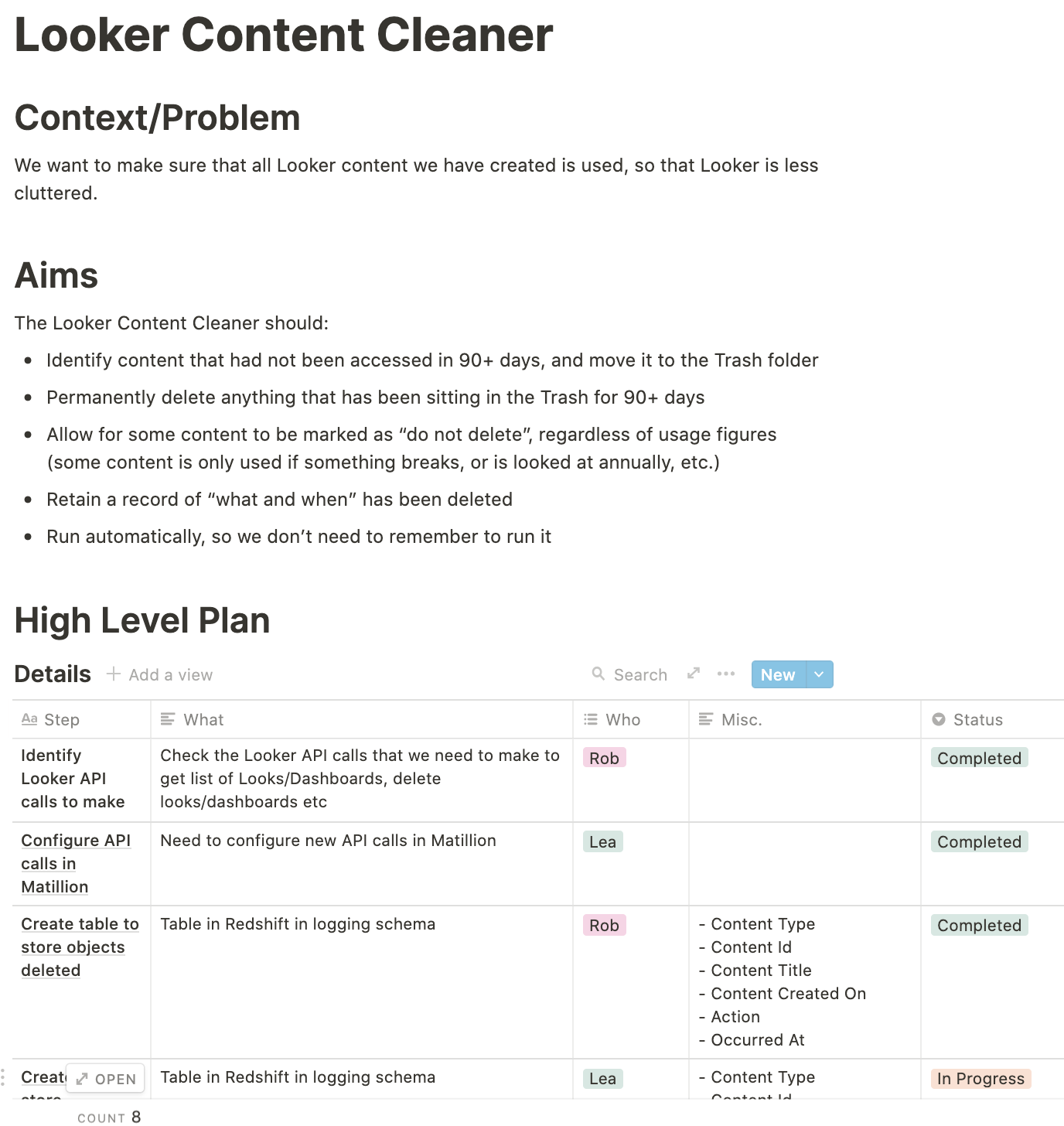
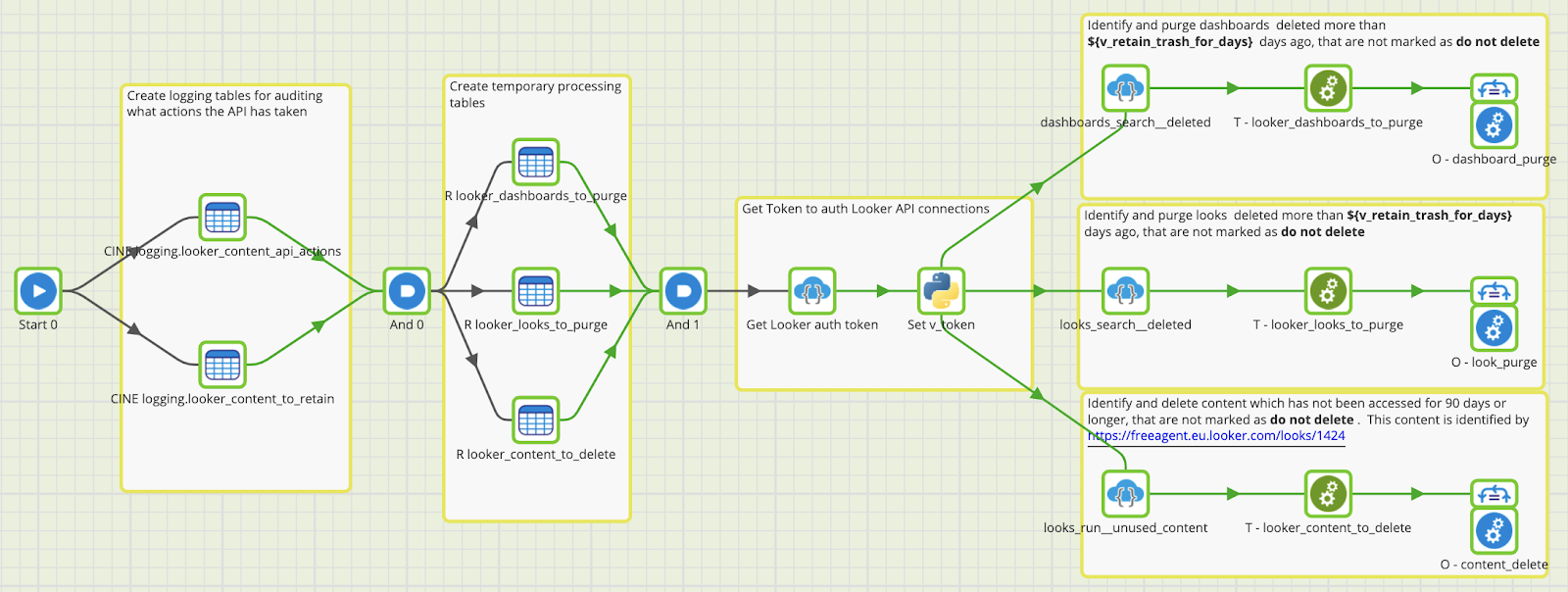
‘How can we use our data to understand and empower our accountancy practice partners?’ This is the question that I posed in my previous blog about delivering practice insights last summer. This question was the foundation for my project last year and is the one I came back to continue answering this year.

To recap how the project was left at the end of last summer; I had created three dashboards that summarised the usage of FreeAgent by accountancy practices and their clients. These dashboards were used by FreeAgent to speak to our accountancy practice partners and inform them of how their clients interact with the app, including:
- Usage of the mobile app/desktop
- Activity by account managers versus end users
- Which clients have not been active for over 30 days
When I finished my last internship, the dashboards were being used frequently to start conversations with the accountants about which areas their clients were excelling in and which areas may need some improvement. There was a lot of excitement from the accountants about getting access to this data, as it was information that they just hadn’t had in the past and it could help them start necessary conversations with their clients who weren’t using FreeAgent as expected.
The buzz and excitement around these ‘Practice Insights’ was even greater than we’d imagined and it got us thinking, ‘How can we make this even better? How can we improve this practice insights project to empower our accountancy practice partners even more?’ and that was the beginning of the proof of concept ‘self-serve’ practice insights tool created over the last three months.
The Problem
I’m going to rewind slightly and first cover a few issues that came up with the practice insights dashboards.
Practices have individual needs
Though the dashboards were really well received, they are certainly far from being a ‘one size fits all’ solution. As someone with no background in accountancy, one thing I have learned throughout this project is that accountancy practices all have different processes, different priorities and different ways of working. Therefore they have different needs on which data should be monitored to help streamline their processes and engage their clients. There was an iterative process of implementing feedback from accountants that allowed us to create dashboards which covered the needs of a broad range of accountancy practices. However, they still are limited to only the information shown on the dashboards, even though we have much more to offer.
Practice dashboards can’t be sent interactively
The practice insights dashboards are interactive. Users can drill into individual companies to get more detail. However, when an accountant is sent this dashboard it is only in a PDF format. This means that they lose the interactivity of the dashboard when being regularly sent it and need to do a screen-sharing call with a partner at FreeAgent to get the detail that they need – and even then they are still limited to data provided by the three dashboards, which is more of a summary rather than a detailed breakdown of what clients are doing.
Practices unable to get granular insights from our reports
To combat the lack of breakdown of information in the practice insights dashboard, my colleague Jack created a ‘Practice Engagement Insights’ report which has a more detailed breakdown of activity for companies in a practice. It can be downloaded as a CSV file and sent to a practice to play around with the data themselves if they want to. However this report is still limited to the activity over the date range we selected and requires the accountants to have knowledge of how to manipulate CSV data in the way they want to.
So to summarise these issues: if the practice insights dashboard is not granular enough and the practice engagement report is not flexible enough, how can we create a product which is both flexible and detailed for the accountants to get the insights they need to help their individual practice? A possible solution – a ‘self-serve’ practice insights product which allows accountants to select the data that they need in the format that they need.
The Solution
Using our business intelligence tool, Looker, we packaged the insights in a way that allowed ‘self-service’ – which is currently being trialled with four accountancy practices. This means that we gave four accountancy practices access to Looker and created a project that allows them to explore their own data and build their own reports, depending on what they are interested in. The data is limited to data dimensions and calculations that we have created for the practices, which are split into four different categories:
- Company API Usage – data on client API usage (which API integrations have been set up and how often they are used)
- Company Key Dates – data on important dates for clients (e.g first and most recent VAT returns)
- Company and User Activity – data on minutes of activity on a client account broken down by users and account managers
- Practice API usage – data on practice API usage (which integrations have been used by the practice)

These categories of data are called ‘explores’ in Looker.

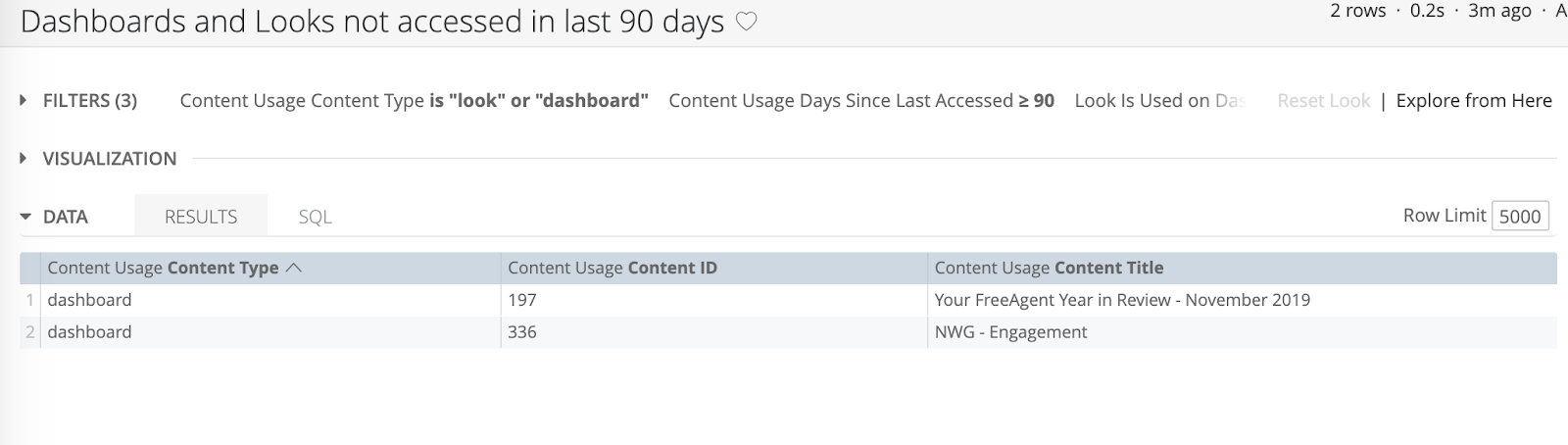
Within the explore, the accountant can pick and choose which data points they would like to see. In this example, the Company and User Activity explore, they could look at the number of minutes spent by the client and the accountant for each company over the last however many days they are interested in.
We are aware that access to this tool could be overwhelming at first, so we also created some example dashboards (based off the previous ‘Practice Insights Dashboard’) to help get them started.

Future of the project
So far we have received a lot of useful feedback from accountants who have trialled the tool. It is interesting to see how the accountancy practices use the tool differently- some find it helping for managing their own practice, but are less interested in details of what their clients are doing. Others find that details of client usage has been incredibly helpful for them to chase up clients where necessary.
A part of the tool which one accountant finds extremely useful, could have less use to another – but this is exactly what we wanted, something with variety, something which can be customised by each accountant to give them what they need. One thing is for sure – they are all excited about getting access to this data.
As for the future of the project? As I mentioned earlier, this is very much an early days ‘Proof of Concept’ idea, to show that this is something that could really be valuable to our accountancy practice partners. So how it could look in the future is dependent on many different variables. That’s the beauty of this project, it has the scope to become something much bigger and much greater, in whatever shape that may be. The bottom line is this, we know that our accountants are passionate about data and we are excited to continue down this path and find the best way for us to get their data to them.