


In late 2022, we restructured our analytics team by aligning each analyst to a different area of the business. In this blog post I’ll talk about what we changed, why we changed it, and how we feel the changes have gone so far.
If you’ve been through a similar process (or even the opposite process!), are considering it, or have any other thoughts, we’d love to chat! Please drop us a comment below.
Some context: our analytics team and its purpose
We’re a business of roughly 250 people with an analytics team of five: our manager, plus four analysts, or “individual contributors” (often referred to as ICs).

We serve the entire business and we do so in many ways, such as:
- Providing stakeholders with access to data and insights
- Supporting stakeholders’ training in all things data related
- Building power tools that magnify the impact that our stakeholders can have.
How we worked in 2022…
Because we serve the entire business, we receive work requests of all shapes and sizes from many different directions. For example, we might be asked to:
- Track and build reporting for our new Smart Capture functionality
- Improve the logic used to calculate customer churn so that the definitions are standardised for our different types of customer
- Create a model to estimate the lifetime value of our accountancy practice customers
- Provide somebody with access to our BI platform, Looker.
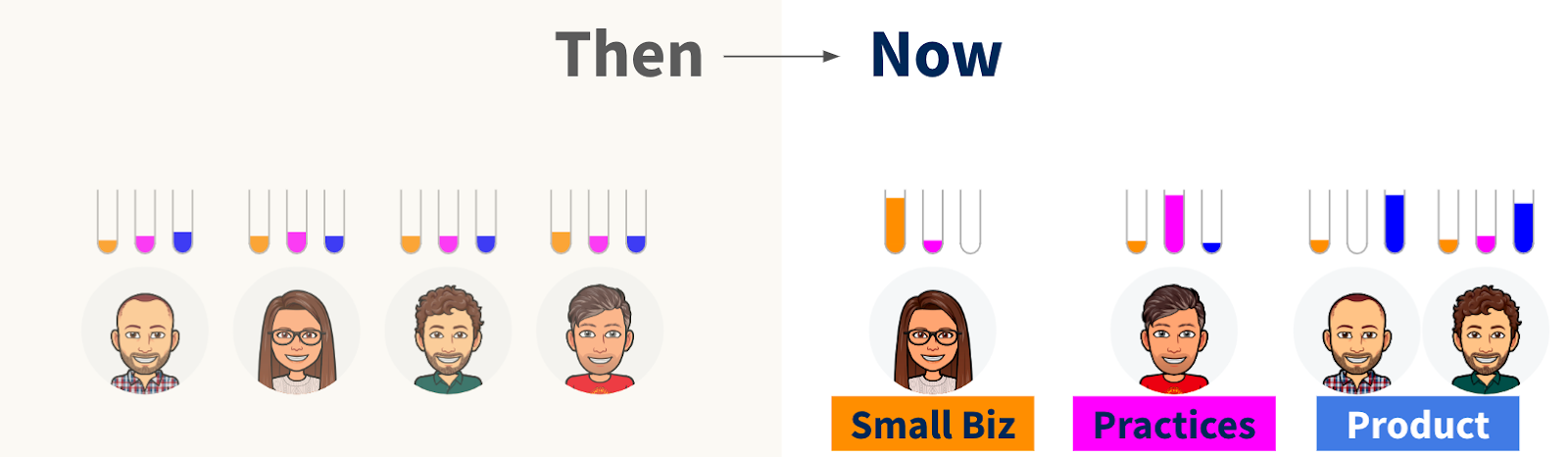
In 2022, any given IC in the team would be equally likely to pick up any given piece of work. We weren’t making distinctions based on where the work had come from, and we didn’t have rules (related to the source of the work request) to determine who should work on what.

We work in eight-week cycles. In practice, that meant that an IC would typically spend one cycle working on a project for one area of the business, then the next cycle working with a different area of the business, and so on.
…and why it wasn’t working
We found that our way of working was causing us some problems.
Problem 1: It was difficult to prioritise work requests correctly
Weighing up lots of pieces of work against each other is really hard when you’re trying to compare them on so many factors, and when each is coming from a different area of the business. We’re trying to decide which is the most important piece of work for the business as a whole, which is an epic undertaking for what should be fairly simple day-to-day prioritisation calls.
Problem 2: It was difficult for ICs to build up domain knowledge
Jumping between different areas of the business each cycle makes it difficult, as an IC, to build up domain knowledge in any particular area. As a result, our understanding was spread quite thinly. We might have had slight “leanings” in some areas vs others, but we didn’t have anything approaching “expertise”.
Problem 3: It was difficult for the team to build stakeholder relationships
Similarly, when you’re being pulled in multiple directions cycle after cycle, working with different stakeholders, it’s difficult to build meaningful working relationships.
Solution: align ourselves with the business’ different domains
We felt that all of those problems inhibited us from serving the business as well as we felt we could, so we tried something new to us: domain alignment.
Carving the business into domains
Ask anybody in the organisation “what different areas does our business have?” and you’ll get a different answer. The right answer here depends on the use case.
For our use case, we wanted to carve work requests and stakeholders into areas – for which we coined the term domains – that are trying to answer similar questions, have similar groups of stakeholders and require similar background knowledge. The domains we came up with were:
- Small Biz – work specifically concerned with our small business customers. Where are they coming from? How long do they stay?
- Practices – work specifically concerned with our other type of customer: accountancy practices and their accountants. Where are they coming from? How long do they stay? What do they do?
- Product – work concerned with how our product itself is being used to help businesses nail their daily admin, relax about tax, etc.
It’s worth stressing the cross-department nature of these domains. Practices, for example, is made up of marketers, our sales team, our product and engineering teams who build practice-specific areas of the app.
That means that we now see work requests through a different lens: which domain have they come from?

Aligning our ICs to those domains
Once we had the concept of domains, we aligned ourselves to them. The IC-to-domain matches were decided based on a combination of technical skill sets, prior domain knowledge, personal development goals and preferences.

Alignment here effectively means “their primary focus is”. Nobody moved to a different department, or had their job contract changed. We still meet daily as a team, pair on things, plan our work together, etc. But we’re now more likely to also attend other teams’ meetings (if it makes sense to, based on our domains).
The rationale behind the domain alignment
This was a pretty significant change in how we work, driven by a combination of some careful thought and a pinch of experimentation. What were we hoping to achieve?
More appropriate prioritisation of work requests
Previously, we were trying to weigh up six pieces of work against each other and make the call ourselves which to prioritise. However, each domain now has its own backlog managed in collaboration with those stakeholders.
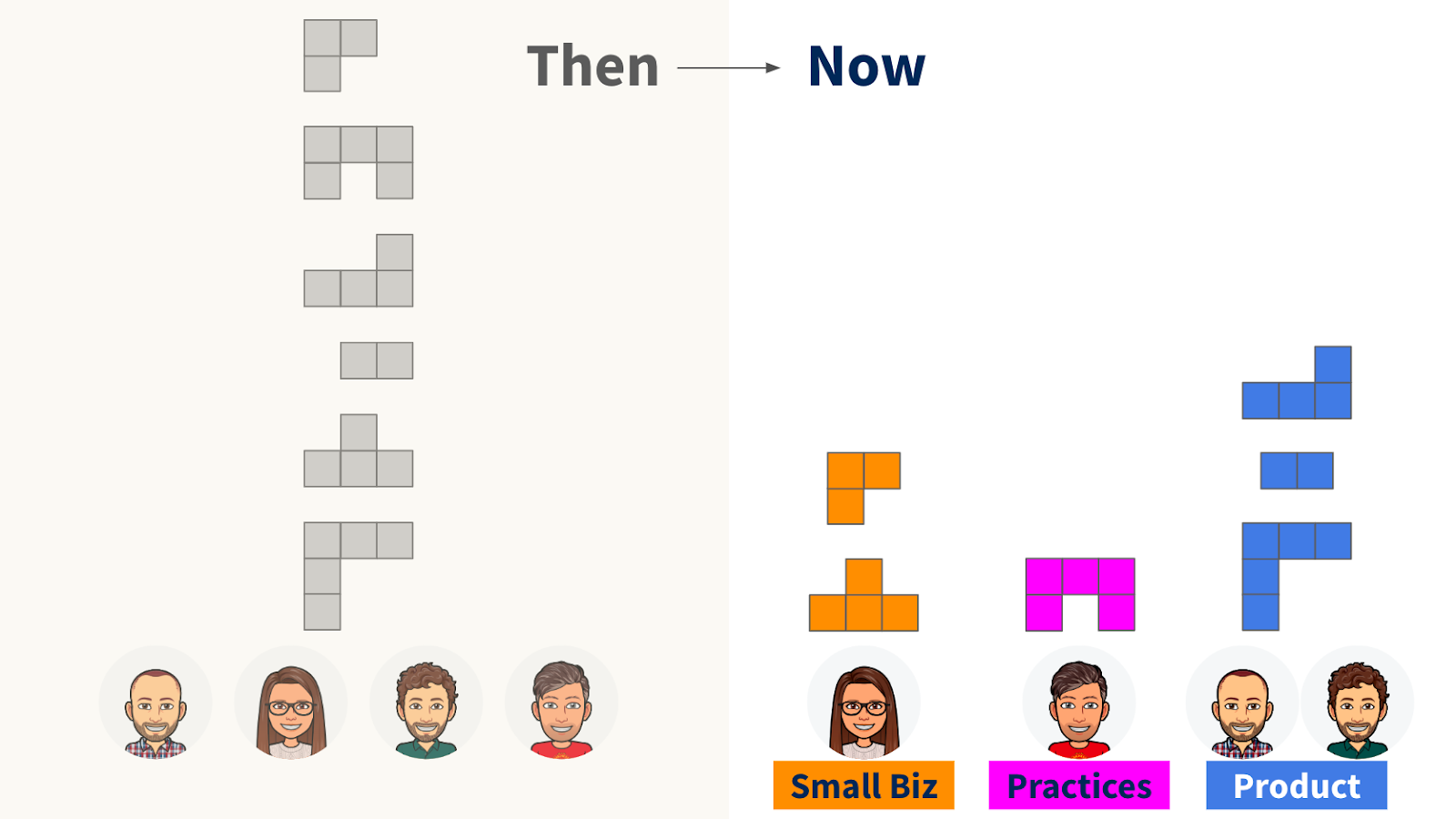
Rather than weighing up six pieces of work at a time, we’re now weighing up two or three. We can have meaningful discussions with each domain about what work is the highest priority, factoring in FreeAgent’s goals as a whole. It’s much easier to compare a bigger apple to a smaller apple, than it is to compare a big apple to a big pear (especially when it’s not clear whether we value apples or pears more).
It’s worth mentioning that some element of underlying pre-prioritisation has already been done implicitly, with our decision to place two ICs on Product reflecting the business’ goals at that time.
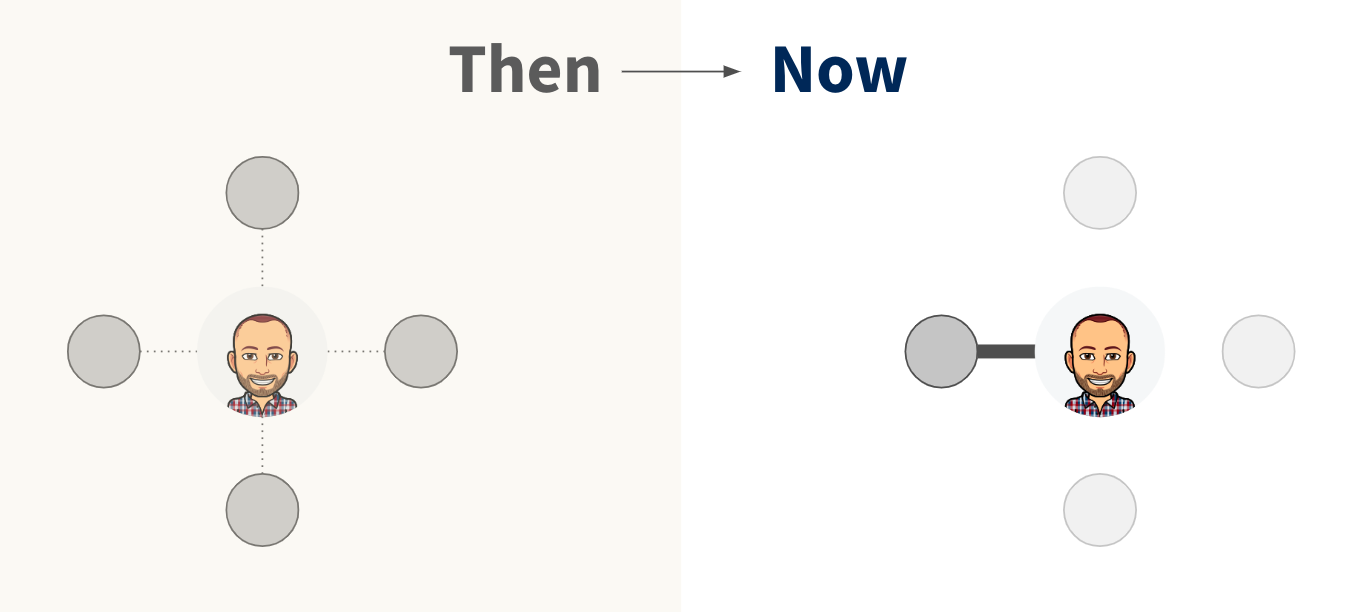
Easier for ICs to build up domain knowledge
Previously, it was difficult for us to build up domain expertise. Now, working consistently in one area of the business makes it much easier for us to build up knowledge in that particular domain.
Not only are we spending less time in other domains, but the reduced context-shifting creates more time in total for us to dedicate to our own domain. Furthermore, attending other teams’ meetings provides a richer foundation of domain knowledge to build on.
Easier to build strong relationships with stakeholders
Rather than dividing our ICs among lots of stakeholders, we’re now each working with the same group of stakeholders from one cycle to the next.
Working with the same people across multiple projects really strengthens the relationship you have with them. You get to know each other’s ways of working, which ultimately improves the work you do.
Reflections on how it’s going
We’ve been trialling this “domain alignment” for over a year now, and we’ve been reflecting on how it’s going.
What’s going well?
Strong ties with each domain
As we begin 2024, the contrast to 2022 is really clear to see. The ties we have with each domain – both at an individual IC level, and also at a team level – are much stronger than they used to be.
New bridge for cross-department domains
As mentioned above, the domains (as we see them) actually cross team and department lines. We see Practices, for example, as the marketers responsible for accountancy practices, our sales team, and our product and engineering teams who build practice-specific areas of the app.
By having an analyst working across all of those teams we see even more communication between those teams – and even more joined up thinking – than we used to. We act as a bridge between those teams.
More work done overall
Specialisation naturally leads to greater efficiencies. Being more familiar with the domain and the technical setup of previous work makes it much quicker to plan and undertake new work, which means we get more done overall.
Clearer delivery commitments
Planning and prioritising work within domains is more transparent than doing it across domains, and we’re able to give more accurate estimates on what work we’ll be able to get done and how long we expect it to take.
What are we still figuring out?
How do we get better at project management?
We’re data analysts, not project managers. Managing a domain and its workload like this taps into strings that aren’t often used on our bow. We’d like to get better at this.
How do we cope with leavers, or big patches of A/L?
This is the flipside of the specialisation benefits. When somebody goes on annual leave for two weeks, we notice it more than we did before. And if somebody leaves, we have an extreme version of that. It’s an inevitable consequence of specialisation, but we’d like to mitigate the risks here as much as possible without losing all of the benefits.
How can we respond to shifts in business priorities?
Having built these relationships and deeply embedded ourselves within these domains, it’s more difficult for us to respond to higher level changes in the business’ priorities. There isn’t a straightforward way for us to “spend more time on Practices work for a couple of cycles” because we’d need to change the structure of our team.
How do we ensure our “platform” work isn’t neglected?
Lots of the work that our team does is domain agnostic. For example, we needed to upgrade from the legacy Google Analytics (Universal Analytics) to the new Google Analytics 4. GA data underpins lots of what we do, so this affects all reporting for all domains. Who works on that? Should we pause work on an entire domain while this goes on? Who keeps tabs on what needs doing on our platform? This is a particularly pressing puzzle for us at the moment.


